Section 3:内容モデル
本節では,内容モデルという,XHTML の理解に重要な役割を果たす概念を導入する。内容モデルは,XHTML において,文書をどのような形でモデル化し,記述するかという根幹に関わっている。
XHTML の文書モデル
復習であるが,XHTML では,“文書がどう表示・印刷されるか”というより,抽象的である“文書の各部分がどのような役割を持つか”に注目してマークアップしていく。これには,(スタイルシートを利用することで)さまざまなメディアに適した出力を得られる,“大きな文字である”よりも“見出しである”と直接書かれていたほうが(たとえば目次を作成するなどという場合)機械処理しやすいという利点がある。
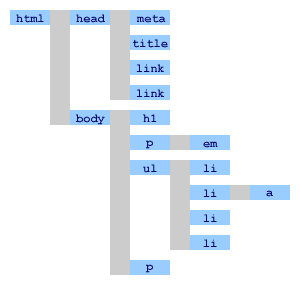
また,XHTML は,原則的に,文書の各部分を要素として,その内容としてテキストを記述したり,ほかの要素を記述したりする。この,要素の中に別の要素が記述されるという“入れ子構造”は XHTML(もっと言えば,XML)の大きな特徴である。XHTML は,html 要素の中にさまざまな要素が入れ子になっている。これを図式的に表すと木のように見えることから,この構造を文書木(図 3.1)と呼ぶこともある。
内容モデル
さて,多くの要素は内容をもつが,どんな要素でも含んでよい,いつでもテキストを含んでよいというわけではない。これは,Let's begin XHTML の Section 2 で,
XHTML では,要素ごとに,その内容に何を含んでよいかが決まっている。要素の内容として,テキストを含んではいけない要素もある。
と触れた。たとえば,パラグラフ(p 要素)は見出し(h1〜h6 要素)を含んではならないし,箇条書き(ul および ol 要素)は項目(li 要素)のみを含む。こういったものがその要素の種類に対する内容モデルである。この内容モデルに反した記述は,直ちに正当な XHTML とはならなくなる。
内容モデルの定義と表現
要素の種類ごとに,直接の要素の内容として含むことができる要素の種類およびテキストの記述の可否が定義される。ここで“直接の”という点に注意されたい。たとえば,ul 要素は li 要素しか直接含んではならず,テキストを記述することは許されないが,li 要素はテキストを含んでよい要素であるので,箇条書きとしてテキストを連ねることができる。
内容モデルは,要素の種類名およびキーワードをいくつかの記号で組み合わせて表現される。
( )- かっこは,数式の記法と同じく,それをグループ化する。
A, B, C- カンマで区切ると,“A,B,C がこの順で出現”を表す。
A | B | C- セパレータで区切ると,“A または B または C からひとつを選ぶ”を表す。
A?- 疑問符を伴うと,“A が 0 または 1 回出現(zero or one time)”を表す。
A*- アスタリスクを伴うと,“A が 0 回以上出現(zero or more times)”を表す。
A+- プラス記号を伴うと,“A が 1 回以上出現(one or more times)”を表す。
#PCDATA- このキーワードは,通常のテキストが出現可能であることを表す。
EMPTY- キーワード
EMPTYは,必ず単独で現れ,その要素が内容を持たないことを表す。HTML との互換性を考慮した XHTML では,内容モデルにこれが指定されている要素は空要素タグ(<... />)で記述する。
たとえば,ul 要素の内容モデルは“li+”であり,“li 要素が 1 回以上出現”を表している。また,dl 要素では“(dt | dd)+”となっており,“dt または dd 要素のいずれかを選択することを 1 回以上”となる。img 要素は内容を持たないから,内容モデルは“EMPTY”である。
これらの表記の詳細は,ここでは覚えていただかなくとも構わない(内容モデルは,その場ごとにことばで解説する)。ただし,XHTML の内容モデルとしては次の形式が頻出するので,これは覚えてしまっていただくのがよいだろう。
(A | B | C)*- A,B,C の中の,いずれも,何度でも出現してよい。“何も出現しない”も許される。
(A | B | C)+- A,B,C の中の,いずれも,何度でも出現してよい。ただし,“何も出現しない”は許されない。
先ほどの dl 要素の内容モデルが後者の形式であることに気づかれるだろう。
“Academic HTML::XHTML 1.1”での内容モデルの表現形式は文書型定義(Document Type Definition:DTD)という,XML での言語定義(スキーマ)言語の記法に従う。スキーマ言語としては,XML Schema,RELAX などがあり,前者を用いて XHTML を定義するプロジェクトが W3C で 2004 年 1 月現在,進められている。
要素の分類
XHTML では,本文を構成する要素をブロック要素(ブロックレベル要素)とインライン要素(インラインレベル要素)に大別する。ブロック要素は,文書中の大きな単位で,パラグラフ,見出し,箇条書きなどが属する。視覚表現では,前後に改行を伴うことが多い。一方で,インライン要素は,文書中の小さな単位で,強調語句,ハイパーリンクのホットスポット,文中引用などが属する。視覚表現では,前後を改行せずつなげていくものが多い。これらを,内容モデルの表現形式で表すと,次のようになる。これは,ブロック要素・インライン要素に属する要素の種類のリストであることにも注意されたい。
%Block.mix;h1 | h2 | h3 | h4 | h5 | h6 | ul | ol | dl | p | div | pre | blockquote | address | hr | table | form | fieldset | ins | del | script | noscript%Inline.mix;br | span | em | strong | dfn | code | samp | kbd | var | cite | abbr | acronym | q | tt | i | b | big | small | sub | sup | bdo | a | img | map | object | input | select | textarea | label | button | ruby | ins | del | script | noscript
さらに,“ブロック要素でもインライン要素でもよい”という“フロー”を定義する。
%Flow.mix;h1 | h2 | h3 | h4 | h5 | h6 | ul | ol | dl | p | div | pre | blockquote | address | hr | table | form | fieldset | br | span | em | strong | dfn | code | samp | kbd | var | cite | abbr | acronym | q | tt | i | b | big | small | sub | sup | bdo | a | img | map | object | input | select | textarea | label | button | ruby | ins | del | script | noscript
ここで,“%...;”という記法は,たとえば“‘%Block.mix;’が現れたら‘h1 | h2 | ... | noscript’に置き換える”程度に理解していただければよい。
XHTML の大部分の要素は,上記の 3 つのいずれかにテキスト(#PCDATA)を加えたものを内容モデルとする。たとえば,h1 および p 要素の内容モデルは“(#PCDATA | %Inline.mix;)*”であり(これは %Inline.mix; を展開すれば“(A | B | C)*”の形式であることに気づかれるだろう),“テキストとインライン要素”となる。確かに,見出しやパラグラフは,それと同列な“文書中での大きな単位”を含んではならないと定義されている。
“%...;”という記法は,Let's begin XHTML の Section 18 で解説した“&...;”で名前を文字列に置き換える機構の仲間で,パラメータ実体参照という。パラメータ実体参照は DTD の中で用い,置き換えの規則が“&...;”の形式の実体参照と異なる点がある。